Dynamics
|
|
Generational Dynamics |
| Forecasting America's Destiny ... and the World's | |
| HOME WEB LOG COUNTRY WIKI COMMENT FORUM DOWNLOADS ABOUT | |
|
These pages contain the complete rough draft manuscript of the new book
Generational Dynamics for Historians,
written by John J. Xenakis.
This text is fully copyrighted. You may copy or print out this
material for your own use, but not for distribution to others.
Comments are invited. Send them to mailto:comments@generationaldynamics.com. |
Early in 2005, the Pentagon announced the Army's Future Combat Systems (FCS). By 2014, just a few years from now, America will be deploying thousands of computerized soldiers that will have the ability to decide on their own to kill people (hopefully, the enemy). In early implementations, kills will be directed wirelessly by human overseers, but as millions of these are deployed, overseeing them will become increasingly impossible. By 2025, super-intelligent computerized robots manufactured in countries around the world will be fighting major battles. By 2030, super-intelligent computers will be running the world without our help.
 |
This is quite a different view of intelligent robots than the one in the movie I, Robot. It came out in summer, 2004, and it portrays a world in 2035 when super-intelligent robots are being manufactured for domestic home use. These robots are designed to be unable to harm human beings, but the story line is about a rogue robot who may be violating that rule. In the end, Will Smith conquers the malevolent robots and gets the girl, and everyone lives happily ever after.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
When the movie came out, I thought that it might trigger a public debate about the Singularity, the point in time, around 2030, when intelligent robots will be more intelligent than humans in every way, and will be able do their own research and development and produce better versions of themselves. The point is called the Singularity because the exponential growth curve will have a bend in it that will turn it sharply upward. After that, technological progress will be extremely rapid, and within a few years super-intelligent computers will be running the world, and will be as much more intelligent than humans as humans are more intelligent than dogs and cats.
However, no public debate occurred. In fact, nothing much at all occurred, except for an occasional article.
On the other hand, during casual conversations, I've asked a number of people if they've seen the movie and what they think of it. I've been surprised that many people seem to be quite aware of the fact that robots / computers are going to be taking over in the not too distant future, but they aren't especially concerned about it.
I guess that this is just the nature of human beings -- people are concerned about their own problems right now, but rarely about other people's problems right now, or even their own problems in the future.
Nonetheless, I still expect that someone will cause this issue to grab the attention of the public.
This is actually a very ambitious chapter that could easily be expanded to a book by itself. Here is what we plan to accomplish:
With regard to this, we note that the Theory of Evolution tells us how natural selection (survival of the fittest) works in individual animals, but has no explanation at all for the mechanism by which intelligent species evolve. We'll make the argument that Generational Dynamics fills in this hole in the Theory of Evolution.
We've frequently pointed out that we're at a unique time in history, because all the countries that fought in WW II are now in generational crisis periods, all at once, leading to a new world war.
But we're at a unique time in history for another reason, because this time is just a few years before the Singularity. For the first time, we're able to look back throughout the entire span of history and see what happened, and what conclusion the human race is likely to reach.
Basically, no one knows what is going to happen after the Singularity. There is a wide range of possibilities, some benign and some horrific, and it's worth summarizing some of them.
The scenario depicted in I, Robot is impossible for many reasons.
First, the movie says that the super-intelligent robots will be designed to follow the Three Laws of Robotics, as formulated by Isaac Asimov in the I, Robot series of short stories that he wrote in the 1940s:
However, the first use of intelligent robots will be in warfare -- as we said earlier, the Army's Future Combat Systems (FCS), to be deployed in 2014, will deploy computerized soldiers capable autonomously of identifying an enemy and killing him. So the first intelligent robots will be specifically designed to kill humans, not programmed to be forbidden to kill humans.
Second, unlike what happens in the movie, there will be no way to control these robots once they're out there. (Insert your favorite Pandora's box analogy here.) Even if America tries to control the development of these robots, there's no reason why other countries will. There'll be a competition among countries to come out with the most intelligent, most deadly, and most productive intelligent robots first.
And there's absolutely no guarantee that "the good guys" will be first. Remember that in World War II, Adolf Hitler's Germany was racing to develop the nuclear bomb first. We won, thanks to some luck and to some brilliant sabotage efforts. But if we had lost, and we might have, then the first nuclear weapons might have fallen on London and New York, rather than two Japanese cities.
At this particular moment in time, America has developed the world's fastest supercomputer, as announced by IBM in September, 2004. However, for the two years preceding, that title was held by NEC, a Japanese company. At the same time, colleges in both China and India are turning out thousands of high-tech engineers, and they'll be working on this problem as well. One of those countries, or perhaps another country, might well take the lead.
We can look at the following rough timetable: By 2010, there will be supercomputers with computing power exceeding the human brains. By 2020, the first "small form factor" super-intelligent servants will be available -- things like intelligent plumbers, intelligent nursemaids, intelligent language translators, intelligent soldiers, and so forth. By 2030, super-intelligent computers will be quite common. They'll be able to improve and manufacture new versions of themselves, and the Singularity will occur.
No one can predict what will happen after that. In one horrific scenario, the super-intelligent computers decide to kill all the humans, and do so within a year or two. Fans of The Matrix series of movies may hope that the humans will win that war, but there's no chance; even if humans win the first battle, the computers will continue to improve themselves very rapidly, so they'll win the next battle.
An even more horrific scenario is the kind of torture you now see only in science fiction stories. In this scenario, super-sadistic super-intelligent computers use advanced biotechnology techniques to keep humans alive for the purpose of continual torture, in order to use them for enforced labor.
However, there is an optimistic scenario: humans coexist peacefully with the super-intelligent computers that run the world; after all, we don't feel the need to kill off all the dogs and cats in the world, so why should the super-intelligent computers feel the need to kill us or torture us?
Indeed, I disagree with some writers who claim that these super-intelligent computers, being only machines, will have no morality. In fact, I disagree fundamentally with the view that morality can come only from religious teachings. I find that morality can come from self-interest, and so I would expect super-intelligent computers to have some kind of morality.
The study of "artificial intelligence" (AI) is almost 50 years old now, and it's not too much of an exaggeration to say that it's been an almost total failure.
For example, AI researchers set goals for computers and computerized robots to be able to see, hear, speak and reason within a few decades. And yet today's robots can't do anything like that. As one person put it, they're dumber than cockroaches.
In fact, almost every important goal ever set for AI has been a total failure. Take chess for example.
In 1957, AI researchers expected a chess-playing computer to be world chess champion within ten years or so, and yet by 1970, the best chess-playing computer was little better than a beginner. The researchers were unable to develop algorithms and heuristics which could mimic the reasoning of a chess master or grandmaster.
AI researchers have never been to develop the necessary heuristics to make computers do anything reasonably.
So if AI researchers couldn't do something "simple" like develop the heuristics to make computers play chess better than a beginner, then how can they possibly develop a super-intelligent computer, able to listen and think and talk and reason?
Well, wait a minute. Today's chess-playing computers are much better than beginners. In fact, today's chess-playing computers play at the level of world championship chess. There are probably fewer than a dozen people in the world today who could win even one game against the best chess-playing computer, and since chess-playing computers keep getting better, there may soon be no one.
So if artificial intelligence has been such a failure, then how did computers get so good in 30 years? Did AI researchers finally figure out a way to improve their software?
Nope. It turns out that the chess-playing algorithms and heuristics used in today's computers are really not much different from the algorithms used in 1970. (The main algorithm is called a "minimax algorithm," invented in the 1960s, and it's still the main algorithm used by today's programs.)
So why are computers doing so much better today? It's because computers are much more powerful. A chess-playing algorithm could only look 3 or 4 moves ahead in 1970, but can look 8 to 10 moves ahead today, because computers are much more powerful.
This example illustrates, in a sense, how much of a failure artificial intelligence research has been. Back in the 50s, 60s, and 70s, researchers were expecting to find elegant algorithms and heuristics that would make computers match humans in a variety of areas -- game playing, voice recognition, natural language processing, computer vision, theorem proving, and so forth. But the fact is that AI researchers have failed to do so in every area.
Instead, they've fallen back onto "brute force" algorithms. The phrase "brute force" was originally meant to be pejorative, but now it's really become the only game in town. What "brute force" means is to use the power of the computer to try every possibility until one works.
Take voice recognition, for example. Today we have several commercially available programs that do a pretty decent job of "taking dictation" -- listening to your voice and typing what you say. To get them to work well, you have to "train" them for many hours, but once the training is over, they can do pretty well.
This is pure brute force technology. The training simply means that you recite dozens of phrases that the computer saves on disk. Then when you dictate, the computer simply compares what you say to the saved patterns until it finds a match.
Voice recognition technology has been getting better all the time. In 1990, they were limited to a vocabulary of a few hundred words. By 1995, the vocabulary was up to 10,000 words, but you had to say each word separately and distinctly, without running words together as you speak. By 2000, they supported continuous speech. As time goes on, they get better and better, because they're able to able to do a lot more pattern matching as computers get more and more powerful.
There's been some algorithmic improvement over the years, but the main difference between 1990 and today -- the power of the computers.
By the 2020s, thanks to vastly more powerful computers, and vastly larger disk space, when you buy a voice recognition program, it will come with billions upon billions of stored voice patterns. You probably won't have to train it, since the computer will be able to compare your dictation with the stored patterns that come with the program. This is not especially clever from an AI point of view, but it shows how well "brute force" algorithms work as computers get more and more powerful.
The same is true of one AI technology after another. In the end, they'll all fall to brute force techniques.
This shouldn't be surprising -- after all, that's how our human brain works. Our brains are exceptionally good at pattern matching and associative memory. When you look at a chair, you don't start to think, "Let's see, it has four legs, with a flat part on top, so it must be a chair." What happens is that your brain instantly compares what you see to all the other things you've previously identified as being chairs, and instantly identifies it as such, and then associates the result with "Gee, I think I'll sit down."
That's how the first generation of super-intelligent computers will work. They'll simply mimic the human brain's capacity for pattern matching and association -- two things that don't work very well on today's slow computers, but will work very well on the powerful computers of the 2010s and 2020s.
 |
The above graph shows that supercomputers have been doubling in power every 1.5 years (18 months). Ray Kurzweil has extended this curve all the way back to card processing machines used in the 1890 census, and shown that the same 18 month doubling has occurred since then, through numerous different technologies. Technology always continues to grow exponentially at the same rate, and so it will continue into the future.
By 2010, large supercomputers will have the power of the human brain. By 2020, small desktop computers will have the power of the human brain. By 2030, small-form computers will have many times the power of the human brain.
The Intelligent Computer (IC) algorithm that I will describe in this chapter uses a variety of technologies, but all of them are brute force algorithms, meaning that the computer's intelligence depends on using the computer's power to "try every possibility."
Let's distinguish between two completely different kinds of brute force algorithms. I'm going to give you two problems.
 |
Take a look at the adjoining picture crowded with furniture. The first problem is to find the clock in the picture. Chances are, you can do so instantly.
Now here's the second problem: Find the prime factors of the number 79439.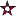 (More simply, just find any numbers that divide into 79439 with no remainder.) Chances are, this problem will take you quite a while longer to solve than the last problem.
(More simply, just find any numbers that divide into 79439 with no remainder.) Chances are, this problem will take you quite a while longer to solve than the last problem.
This timing difference is counter-intuitive. Finding the clock in the above picture should be a long, time-consuming job. You'd have to search through boundaries between different colors, and identify a region of the picture that appears to identify something with the "clockness" attribute.
On the other hand, finding the prime factors of 79439 looks like a much smaller job, requiring much less work. So it's surprising that this problem takes much, much longer to solve.
The reason that the brain solves the first problem so quickly is that it uses a kind of "brute force" algorithm of its own. When you look at the picture, your brain instantly compares it to millions, billions or trillions of pictures already stored in your brain. All of these comparisons are done simulatenously, so that they can be performed instantaneously. Your brain spots the clock because it matches it up to clocks that you've seen before.
The second problem looks like a much smaller job, but your brain has to solve it a step at a time. You first see if 79439 is divisible by 3 (without a remainder), then you see if it's divisible by 5, 7, 9, 11, 13, and so forth. Your brain has no capacity to try all these divisions simultaneously, and so it takes a long time.
The IC algorithm will work functionally pretty much like the human brain does. Identifying the clock will be done by using massively parallel computing to compare the picture to millions, billions or trillions of pictures already stored in the computer's memory. The first version of the IC will take a long time to be "trained," of course, just as it takes a long time for children to be "trained" to recognize objects, but in the end it will work just as fast or even faster than the human brain, since computers will soon operate faster than the human brain.
In solving the second problem, the computer will have a great advantage over the brain. Both the brain and the computer solve the problem by trying all poosible divisors, but the computer can try each divisor much more quickly and the computer can use parallel computing to try many divisors simultaneously.
Some people claim that the human mind is infinite, and that no finite computer program could possibly match the power of the human brain.
Actually, the human mind does not have infinite possibilities. The human mind has many limitations, and can only think about things it knows about, and in ways it knows about. When you figure all the possible combinations of things that a human mind can think about, it's a very huge number, but it's still finite. Super-intelligent robots will be able to think about a much more huge number of things, and will be able to do it faster.
I use the word "granular" to describe how your mind works functionally. You don't think, "I'll move my right foot 13 inches forward, and then I'll move my left foot 12.3 inches forward." Instead, you think, "I'll walk into the next room," and your feet automatically move as many inches as necessary.
You don't think, "I'll move my hand 5 inches." You think, "I'll pick up that pencil," and your hand moves however many inches are necessary.
So at any point in the day, you really have very few functional choices as to what you can do next.
When you get up in the morning, you might or might not take a shower, you select from five different outfits to wear in your closet, you choose between eggs and cereal for breakfast, and you decide whether to take the bus or take the car to work.
Even if you do something "wild and unpredictable," that'll be something like skipping work and visiting a museum.
So what it comes down to is this: Your mind is not infinite, and you do not have an infinite number of choices. You have only a few choices at each point in the day, and that includes even the "wild" choices.
What about "unpredictable" choices? You might skip work today, and visit a new shopping center you've never been to before, or take a walk in the woods. And something unexpected might or might not happen. But it's still only one or two more choices.
Now, you might argue that I'm simplifying things too much, that the mind really has a lot more choices when you consider that you can do the same thing many different ways. For example, I'm considering picking up a pencil as a single "choice," but you might argue that I could pick up a pencil with my left hand or right hand or with different fingers, etc., or I could nudge the pencil closer and then pick it up a different way, etc., etc.
From our point of view, that doesn't make any difference. We're talking about a super-intelligent computer making functional choices. If the choice is to pick up a pencil, then it makes no difference whether a human picks it up with his fingers or a super-intelligent computer picks it up with a motorized wrench. The point is that the pencil gets picked up.
Similarly, if a human being decides to kill someone by picking up a gun and shooting him, and a super-intelligent computer decides to kill someone by activating the computer's own gun, built in to its hardware, then it makes no difference, because in the end, the other guy's still just as dead.
What about things involving creativity, such as inventing new things?
I've looked at two different examples.
Example: Thomas Alva Edison's invention of the incandescent bulb. Edison's invention of the light bulb didn't involve some magic epiphany where the "infinite" human mind suddenly grasped an entirely new concept that no one had ever thought of before. In fact, he and a lot of other people already knew what had to be done. In order to invent a working light bulb, there were a number of different choices of materials to use for the filament, for the enclosure, for the gas to be used in the enclosure, and so forth. Just to make it more clear, an electric light bulb had already been "invented" several times earlier -- by Humphry Davy in 1800, by Joseph Swan in 1878, and others. The problem with the other designs was that the filament burned up too quickly, so the bulb was impractical. What Edison did was to experiment with thousands of different filaments to find just the right materials to glow well and be long-lasting, and he ended up with a carbon filament in an oxygen-free bulb. There were probably tens of thousands of different combinations of choices. Edison was the first to put together the right combination of choices and patent it. There were many people working on the same thing, including Joseph Swan, who actually came up with a different design that was better than Edison's, but only after a few more months had passed.
The invention of the light bulb illustrates the issues. There was no magic here. What Edison did was hard work. He tried thousands of combinations of things until he found one that worked.
When we talk about super-intelligent computers being able to invent new things, we mean the same thing. Super-intelligent computers can also try different combinations of things, except that they can do it much faster than humans can.
That's how "brute force" works. There's no magic to building a super-intelligent computer, provided that your computer is powerful enough. It's just finding a way to program the computer to try all possible solutions to a problem, until one of them works. That's the way humans do it, and that's the way that computers will do it, except they'll do it much faster.
Example: Andrew Wiles' proof of Fermat's Last Theorem. This is an example of some of the most creative thought possible. Fermat's Last Theorem is a mathematical theorem that's been baffling mathematicians literally for centuries. During those centuries, hundreds of prizes have been offered to anyone who could mathematically prove or disprove this theorem. In the early 1990s, Andrew Wiles applied a new branch of mathematics to the old problem, and came up with a very long, complex proof. However, when he publicized his proof, mathematicians around the world found a flaw in it, buried very, very deep in the middle. Wiles tried for months to fix this flaw, and was just about to give up, and throw his proof on the garbage heap that contained hundreds of failed proofs that came before his. But before giving up, he looked at the flaw in a slightly different way. Here's how his epiphany is described by author Amir D. Aczel:
Wiles studied the papers in front of him, concentrating very hard for about twenty minutes. And then he saw exactly why he was unable to make the system work. Finally, he understood what was wrong. "It was the most important moment in my entire working life," he later described the feeling. "Suddenly, totally unexpectedly, I had this incredible revelation. Nothing I'll ever do again will." At that moment tears welled up and Wiles was choking with emotion. What Wiles realized at that fateful moment was "so indescribably beautiful, it was so simple and so elegant and I just stared in disbelief." Wiles realized that exactly what was making [his proof] fail is what would make [another] approach he had abandoned three years earlier work. Wiles stared at his paper for a long time. He must be dreaming, he thought, this was just too good to be true. But later he said it was simply too good to be false. The discovery was so powerful, so beautiful, that it had to be true. ...
Wiles wrote up his proof using the corrected ... approach. Finally, everything fell perfectly into place. The approach he had used three years earlier was the correct one. And that knowledge came to him from the failing of the [previously attempted] route he had chosen in midstream. The manuscript was ready to be shipped out. Elated, Andrew Wiles logged into his computer account. He sent email messages across the Internet to a score of mathematicians around the world "Expect a Federal Express package in the next few days," the messages read.
This is the story of one of the most exciting and creative discoveries in the history of abstract mathematics. But Wiles' discovery was not manufactured from nothing. His solution came from a new branch of mathematics that he had learned in the 1980s, and by modifying a failed attempt he had tried three years earlier.
This is what creativity and inventiveness are all about. It's taking things you already know, and combining them in new ways that no one every tried or thought of before.
And the point, of course, is that a super-intelligent computer can do this much faster than a human brain can. A super-intelligent computer could have invented the light bulb or proved Fermat's Last Theorem in exactly the same way that Edison and Wiles did -- by trying different things until one works.
This is the "brute force" method for inventing new things and proving mathematical theorems. It doesn't require any sophisticated artificial intelligence heuristics. Like the solution to the problem of playing world championship chess, it only requires trying one thing after another, until something works. And with computers getting faster and faster every year, computers will be able to do exactly these same things, but increasingly better than humans can.
Technology advances by a series of inventions. Scientists invent new things by combining previous inventions, in the same way that Edison invented the light bulb by combining a carbon filament with electricity and a glass enclosure. For most inventions, this occurs because the scientist tried many, many different things, just as Edison tried thousands of materials as filaments.
The speed with which scientists can invent new things is limited by (among other things) the power of the human brain, and the speed with which it can consider different combinations of previous inventions. Thus, new inventions throughout history have occurred at a certain rate, a certain exponential growth rate.
As long as computers are less intelligent than humans, new inventions will proceed at exactly that same exponential growth rate. For example, computer power will continue to double every 18 months.
But one day soon, probably around 2010, supercomputers will be as powerful as the human brain. Sometime after that, by 2015 or 2020, intelligent computers (ICs) will begin to take on special purpose tasks. There'll be IC soldiers, IC nursemaids and IC plumbers, for example. At this time, ICs will still be monitored and directed by human beings.
During the 2020s, it will be more and more convenient to allow autonomous ICs to take independent actions without monitoring or supervision, and by 2030 autonomous ICs will be doing their own research and inventing new things, including new versions of themselves.
 |
At that point, there'll be a change: since the new inventions will be done by IC scientists with more powerful brains than humans, the rate of new inventions will speed up. Thus, the previous rate of technological advance will speed up significantly, causing a bend in the exponential growth technology curve shown in the adjacent graph.
This bend is called "The Singularity." It will possibly be the most important time in the history of humanity, because it will signal the time that there'll be a new "species" of life on earth, superior in intelligence to humans.
No. No way. It's impossible. The Singularity cannot be stopped. It's as inevitable as sunrise.
Can we decide not to invent the super-intelligent computers required for The Singularity? No way. Even if we tried, we'd soon be faced by an attack by an army of autonomous super-intelligent computer solidiers manufactured in China or India or Europe or Russia or somewhere else.
Will the "clash of civilizations" world war prevent development of the super-intelligent computers? No way. Every country will make this technology their highest priority, even in time of war.
At the beginning of this chapter we described the Pentagon's "Future Combat Systems" technology, which will deploy waves of IC soldiers beginning in 2014. The IC soldiers will be programmed to kill people, and if America is doing it, then you can be certain that China and other countries are also doing it.
Is the 2030 date correct? That's the date that I came up with in my own analysis early in 2004. All the analysis I've done since that time not only convinces me that the Singularity will occur by 2030, but also makes it appear that it may occur as early as 2025 or 2020.
No, we cannot stop the Singularity. All we can do is embrace it, and look for a way to limit its harm to the human race.
We will control the first version of the software that runs the super-intelligent computers. The second and future versions will be developed by the ICs themselves. So all we can do is try to design the first version of the ICs so cleverly that future versions will "do the right thing."
This requires some speculation about what will happen after the Singularity.
I saw one web page which said the following: "Anyone who says he knows anything that's going to happen after the Singularity is crazy, because no one has any idea what's going to happen."
I agree with that. A whole new super-intelligent species will be running things, and we have no way of knowing what they'll do. They may kill all the humans, or they may enslave us as laborers to provide supplies for them. They may treat us all the same, or favor one group over another.
Or they may leave us alone, provided that there aren't too many of us.
 |
Or they may serve us, since even super-intelligence has no intrinsic purpose. Maybe they'll grow food for us and build houses for us. They may provide each of us with a "personal assistant," a super-intelligent computer that will provide us with answers to get through the day, and hopefully the personal assistant won't just turn into a slavemaster. Maybe they'll even satisfy all our fantasies, by providing each woman with a personal assistant that looks like Arnold Schwarzenegger in Terminator, and each man with a personal assistant that looks like Kristanna Loken.
These all sound like science fiction, but the Singularity is not. It will be here, with near 100% certainty, by 2030, and whatever happens after that will be unrecognizable by today's standards.
Humans will have one and only one shot at influencing what will happen after the Singularity, and that's the implementation of the "Intelligent Computer version 1.0." IC v 2.0 will be developed by IC v 1.0, and each new version will be developed by the preceding version.
Early in 2003, I was challenged online to come up with a software design for IC v 1.0, the first intelligent computer.
I did so and posted the result online. The outline will appear later in this chapter.
It turned out to be almost a kind of mystical experience for me, an epiphany. Actually digging into the details of how super-intelligent computers would realistically work in the next 20 years
Before then, when I talked about the Singularity, it was very abstract, as if I'd plugged some numbers into an equation and come out with an answer without really having a good feel for why the answer is true.
Now however, the whole thing is much more real to me. I can see how the Singularity is going to play out. I can see what steps are going to come first, and what steps are going to come later. I can see where things can go wrong, and what we have to watch out for.
Most important, I can now see the possibility of a positive (for humans) outcome from intelligent computers (ICs). I used to think that there would be no controls whatsoever on ICs, because any crackpot working in his basement can turn out an IC willing to kill any and all humans.
But now I see that building the first generation of ICs is going to be a huge project, from both the hardware and software points of view, and that the first implementation will probably be the only implementation for a number of years. If the first implementation contains the appropriate safeguards, then it will be possible to get past it to new generations of ICs developed by ICs themselves, and pass those safeguards on to the next generations. By the time that ICs are as much more intelligent than humans as humans are more intelligent than dogs and cats, the critical period will be past, and there'll be no more need for the ICs to kill all the humans.
It'll be like the Manhattan project - only one or two countries will be able to afford to build it at first, and others will have to catch up. Just as it took several decades for nuclear weapons to become widely available, it should be impossible for most other countries to come up with a major implementation before the Singularity actually occurs. That way, the Singularity can be controlled through the critical period.
What are some of the things we can do in implementing IC v 1.0 that will make it more likely that the scenario following the Singularity will be a benign one?
There are certain problems in the implementation of the first super-intelligent computers that we can try to avoid.
Most of these problems are related to setting and achieving goals. Goals are a very important part of the IC software, and there are many problems that can arise if goal-setting and achieving goals is not implemented correctly.
One thing that can go wrong was part of the plot line of the movie Terminator III, where the Skynet computer became "self-aware" and decided that to protect itself it needed to kill all the humans.
What does "self-aware" mean? What does it mean in a human being? Are dogs and cats and other animals self-aware? Are bumblebees self-aware? Most people seem to believe that they are. So what would it mean for an intelligent computer to be self-aware? What does "self-aware" really mean?
Take a look at your desktop computer. Is it self-aware? I think most people would say it wasn't. In fact, suppose you picked up a sledgehammer and started using it on your desktop computer. Would your computer try to defend itself? I sure hope not.
But now suppose some future computer did attempt to defend itself from your sledgehammer blows. Suppose, for example, that it could "see" you coming, and it tries to scurry away and hide so that you couldn't hit it. Such a computer would appear to be "self-aware," because it was trying to protect itself.
After discussions with many people, I've come to the conclusion that this is what "self-aware" means: Something is self-aware if it has self-preservation as one of its goals.
The ICs that we design are going to be able to set goals and achieve them, and one of those goals is going to be self-preservation. For example, if you send an army of IC soldiers into battle against an enemy, then each IC will have at least two goals: killing the enemy, and preserving itself. There'll be other goals as well.
Goal-setting is very important in the IC algorithm. But it's going to be important to make sure that it's done very carefully.
You'll know what the "zero tolerance" problem is if you've ever read in the news about situations where the principal of a school with a "zero-tolerance drug policy" decides to punish and suspend a six year old girl who comes to school with a Tylenol tablet, because Tylenol is a "drug."
This may seem like an easy problem to solve, but it's actually quite complex. In order for the IC to function, it's going to have to follow certain rules.
Humans have to follow rules too, but we also use "common sense." If a rule is going to hurt somebody needlessly, then we're allowed to say, "I'm not going to follow that rule. That rule doesn't make sense in this particular case."
How do we tell a computer to follow certain rules, and then tell it also that it only has to follow the rule when it "makes sense"? What does "makes sense" mean? That's the problem.
The first versions of intelligent computers will make decisions based on rules and priorities given to them by the programmers.
For example, the first IC soldiers, which will be on the battlefields by around 2015, will be following programmed rules for how to kill enemy soldiers. Some of the rules might be, "The enemy soldiers wear xxx-colored uniforms," or "The enemy soldiers are carrying yyy-type weapons."
Of course, in 2015 most decisions will be made by human beings monitoring and controlling the ICs, though the whole point is that some of the decisions will be made by the ICs themselves.
But 2015 is only ten years off. Each year after that will see more and more sophisticated IC soldiers. Each year, the IC soldiers will be able to make more and more decisions by themselves. By 2025, when another ten years have passed, there will be so many IC soldiers, and they'll be involved in such complex operations, that they'll probably be almost completely autonomous, making almost all life-or-death decisions by themselves.
The visceral fear is that this army of autonomous computer robots will suddenly go out of control and start killing everyone.
How could that happen? The most likely way is something like the "zero tolerance" problem -- the IC algorithm contains some rules that produce some unanticipated results.
If you want to write a computer algorithm to give a computer "judgment," so that it "does the right thing," then one way is to provide a set of rules and priorities that the computer can follow.
We all follow rules as we go through life, everything from keeping your elbows off the table when you eat to calling 911 in an emergency. The rules of life are incredibly complex. They ought to be, since they take us decades to learn them, and in fact we never really learn them all.
We'll be addressing the rules of life later in this chapter, but for now we want to focus on a relatively simple set of rules, the rules for playing a good game of chess.
What we want to show is that even a simple set of rules and priorities can lead to really astonishing, unexpected results. We'll show an example of this in a brief computer chess game.
There are two kinds of rules of chess: The rules of chess are ironclad. The computer must follow those rules to the letter. There are no exceptions.
But there are other rules, the rules of playing good chess. Here the rules are much softer: You try to avoid losing material, you try to protect your King, you try to develop pieces in the opening, and so forth. These rules are not ironclad, but they do have different priorities; for example, it's bad to lose material, but it's worse to get checkmated.
These are all perfectly obvious rules and priorities, but they can lead to astonishing results, as we'll show in the next example.
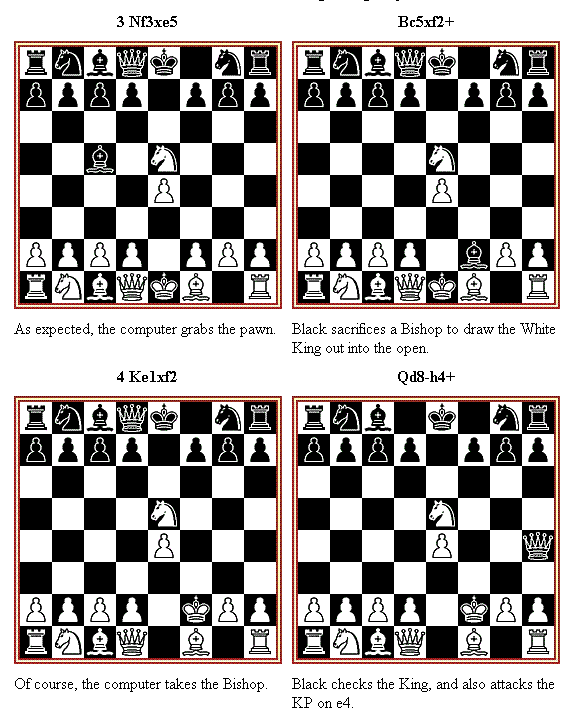
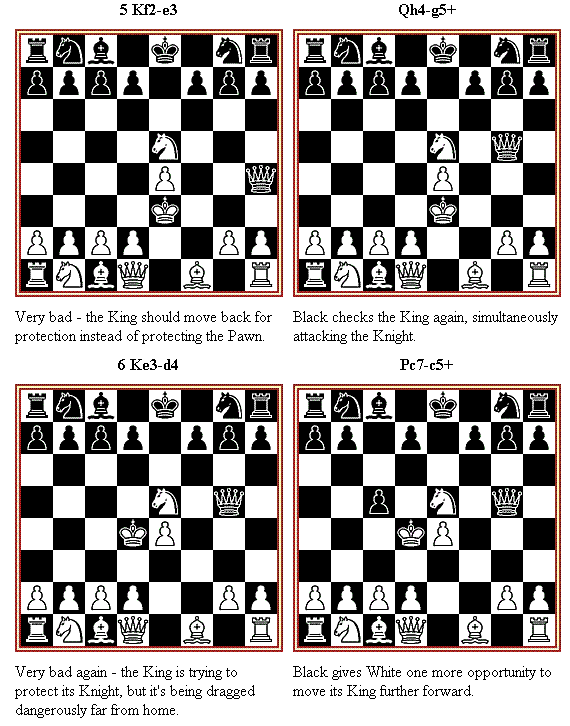
Back in the 1980s, international chess master Julio Kaplan wrote a book on chess computers, and published a sure-fire way to beat almost every chess computer, or the "novice" mode of stronger chess programs.
This is such a perfect example of the "judgment" problem, I want to describe it here, and show how it illustrates the problem.
The way to beat almost every (novice) chess playing program is shown in the following diagrams. If you know how to play chess, take a moment and go through this game, and see why the computer loses:
|
All chess playing software is programmed to (1) Make moves that protect your own King or attack the enemy's King; and (2) make moves that gain or preserve material.
The problem is the balance between the relative priorities of these two rules. In the game above, the computer gives too much weight to gaining and preserving material, and not enough weight to protecting its King.
You might think that this situation would be easy to fix. All you have to do is make the computer protect its King.
But that won't work either, because in many middle game positions, you want the King to move toward the center if that means protecting or capturing pieces.
So this problem is not easy to fix; in fact, it's very difficult to fix.
The "novice" mode chess programs can look ahead only three or four half-moves, so when the computer plays 6 Ke3-d4 in the above game, it can't see far enough ahead to realize the danger the King is in. The more powerful chess computers can look ahead 10 or more half-moves, and so they see the danger earlier.
This is exactly the kind of problem that the Intelligent Computers (ICs) will have to solve in a wide variety of situations, and it represents a significant problem in the development of the IC algorithm.
Now, if this kind of astonishing result can happen in a relatively simple set of rules for playing a game a chess, then what will happen in the "rules of life," which are infinitely more complex than the rules of chess.
This is a very serious problem because there's really no solution to it. It would be nice if you could use simulations to test your software for every possibility, but you couldn't even do that with chess, let alone with the rules of life.
It's worthwhile remembering that human beings constantly fail at the rules of life. For example, your parents tell you that you shouldn't lie, but then you discover that you really shouldn't tell your grandmother that you don't like what she's wearing.
The rules of life are complex and contradictory. Every human being has to stumble through life trying to learn them, and often failing.
An intelligent computer will have the same problems. Even if it only has to learn the rules of good soldiering, those rules alone are so complicated that there's no way to make sure that an intelligent computer won't run into trouble following them.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
I don't mean to pick on the Chinese particularly, but this is something any of several countries might try to do.
We began this chapter by noting that the Pentagon plans to deploy thousands of intelligent computer soldiers by 2014, and probably millions of them in the years to follow. The first robots will be carefully controlled by human overseers, in particular if the robot is about to kill an enemy solidier, but as the numbers of them grow and as they're involved in more complex battles, there will soon be large armies of computerized robots making their own decisions to identify and kill the enemy.
The robots that the Pentagon is planning will be very carefully designed not to become out of control killers, but the same care may not go into robot soldiers manufactured in other countries.
For example, the Chinese may decide to manufacture millions of robot soldiers programmed to recognize physical characteristics of a Chinese person. These robots may have some amphibious capability that allows them to swim across the Pacific Ocean to North America, or they may travel overland through Asia to Europe, programmed to "kill anyone you see who is not Chinese."
What would be the purpose of such a project? In the case of the Chinese, whom we're simply using as an example, the strategy would be as following: Once the Singularity occurs, the computers will take control of running the world. They'll have no particular reason to kill all the humans, the reasoning goes, provided that there aren't too many of them. Thus, by killing off all non-Chinese humans, it's more likely that the Chinese race will survive the Singularity.
There's little doubt that such a war strategy will be tried by some country or other, though it may not have the desired results: when other countries figure out what's going on, they'll manufacture their robots to "kill only the Chinese" (once again, just using the Chinese as an example). Still it's a problem that will have to be addressed, and with the first deployments due in just a few years, it will have to be addressed sooner rather than later.
Let's begin with a block diagram of the first version of the Intelligent Computer (IC) software algorithm:
 |
This block diagram specifies some of the major functions. The vision and hearing units are the "senses," and the logic unit does reasoning.
"But," you may object, "this isn't how the human brain actually works."
That may be true, but we don't care. We're describing how a computer will perform the functions of a human brain. It makes no difference how it does it, whether it does it the same or differently than the way a human brain would do it.
How will the intelligent computer see things and hear things?
Artificial intelligence researchers have been working on this problem for decades. Originally they had hoped to develop mathematical heuristics which would permit computers to see and hear. However, nothing has really worked, and today the only method expected to work is brute force.
This is actually how the human brain works.
When you look at a chair, you recognize it instantly as a chair, because your brain instantly compares what you're looking at to zillions of images in the brain, until it matches to something that you know to be a chair.
This is exactly the kind of "brute force" method that computers will use. And this reflects a trend that's been going on in computer design for a number of years now.
Most computers have always been able to do only one thing at a time; that is, a computer executes one instruction, and then executes the next instruction.
But more and more we're seeing "multiprocessor" computers. Each of the processors within the computer can work independently of the others, so if there are two processors, then the computer can work on two things at once. This is called "parallel computing."
But two processors isn't the limit. There are "massively parallel" computers which have 64,000 or even hundreds of thousands of processors. Within 15 or 20 years, massively parallel computers will have millions or tens of millions of processors.
Computer vision will be made possible with this architecture. It will be possible for computers to recognize a chair by comparing what the computer sees to millions of other images stored in the computer's memory, in the "vision pattern database" shown on the block diagram. These comparisons will be done in parallel, using the computers millions of processors. Thus, a computer will recognize a chair in pretty much the same way that the human brain does.
Computer "voice and sound recognition" is the problem of having a computer hear sounds, identify human voices and specific known sounds, and then hear and distinguish the individual words that are being voiced within the sounds.
Once again, voice and sound recognition will be done with massively parallel comparisons of each sound to sounds that have previously been stored in the computer's memory "sound pattern database." This "brute force" method will allow a computer to hear and understand what human beings are saying.
What about the other senses -- touch, smell and taste?
Scientists today have some idea of how to implement computer vision and computer voice recognition, but touch, smell and taste are really far from realization. There is simply no way to "input a smell" into a computer, let alone recognize what's being smelled. It's very likely that these three senses will require a great deal more research on biotechnology.
A train travels at 30 miles per hour halfway from New York to Chicago. How fast must the train go for the rest of the trip to average 60 miles per hour for the entire trip?
It takes a while for your brain to solve a puzzle or problem like the preceding one. More difficult problems might take you hours, days or weeks.
Contrast that to how quickly your mind can see a chair and recognize it as a chair. Recognizing a chair is done in your brain with massively parallel pattern matching, while solving a puzzle requires time-consuming logic.
Now we're going to outline the algorithm that will be used in the first versions of intelligent computers to learn and perform logical reasoning, with the intent to solve problems. This is a very rough outline.
We'll be referring to this as the Intelligent Computer algorithm or IC algorithm, since it's the heart of the logic of the software.
We'll use another abbreviation, KB = "knowledge bit," to refer to bits of knowledge that are assembled together for learning purposes. We'll show how KBs are combined like jigsaw puzzle pieces to create new KBs.
We're going to be talking about intelligent computers "doing things."
As we'll see when we discuss the algorithm, the first versions of ICs will not be able to do everything, because the computers will not be sufficiently powerful. Instead, there'll be ICs that are "experts" at certain things.
The first ICs will be soldiers, because all new technology is used first for war.
As another example, an expert IC plumber would have an arm whose "hand" is an adjustable wrench. This same arm might have an "eye" on the end of it, so that it can see behind walls. Try to get a human plumber to do that!!!
Other special purpose robots might do household chores, clean up environmental waste sites, provide language translation, act as 24 hour a day home care nurses, or act as soldiers in war where people get killed.
As the ICs become increasingly powerful, it'll be possible at some point for a single computer to "do it all."
The IC algorithm requires putting together little bits of knowledge to get bigger pieces of knowledge. There's a partial analogy to putting together jigsaw puzzle pieces, so let's look at how to solve a jigsaw puzzle.
If you have a puzzle of say 1000 pieces or so, then you look for clues that might make it easier to fit pieces together. You look for pieces of similar color, and you look for edge and corner pieces. Those are techniques for reducing the complexity of the problem.
There's another method you could use to solve this puzzle: You could try to match every piece to every other piece trying to find matches. In fact, this is what you'd have to do in the case of one of those "Deep Blue Sea" jigsaw puzzles where all the pieces have the same solid color blue.
But in either case, the computer has a big advantage over the human being, and this is worth noting.
The computer can "look" at all 1000 pieces, and store their images into its temporary memory. It can then "solve" the problem entirely in its memory, and assemble the final puzzle quickly afterwards.
Humans do not have the ability to quickly learn the shapes of 1000 jigsaw puzzle pieces, and then match them up in their minds. Human beings cannot quickly learn 1000 facts of any sort. Things like learning multiplication tables, or lists of vocabulary words, or lists of historical dates are very painful and time consuming for most humans, but are very easy for computers.
This is a very big advantage for computers in many ways. Consider learning a foreign language. Once one computer has learned it, then any other computer can simply load the same software. Human beings are different. A human takes years to learn a foreign language, and then the knowledge can't be transferred to another human being.
This is one reason why computer knowledge will shoot ahead of human beings, once they reach a certain "tipping point" of intelligence. This ability to temporarily "memorize" lists of things quickly and then use the list for problem solving "in one's head" can be used not only for jigsaw puzzles but also for warfare, research and all kinds of problem solving.
I'm going to describe how an intelligent computer learns, by combining bits of knowledge the way you combine jigsaw puzzle pieces.
A "knowledge bit" or KB is such a bit of knowledge. It will be possible to combine KBs analogously to how jigsaw puzzle pieces are combined, with the following capability: When a bunch of KBs are combined in a meaningful way. the result is a new KB which can be further combined with others.
Returning to the jigsaw analogy, we know that a puzzle piece has certain attributes -- things like colors, edge shapes, and so forth. Human beings especially use colors as clues to find adjacent puzzle pieces.
Well, what are the attributes of KBs?
At first I thought that a KB would have no attributes whatsoever. After all, a human baby's brain starts out as a "clean slate," able to learn anything. Assigning attributes would only limit the ability of the intelligent computer to learn unfamiliar things.
So attributes like color are not part of any KB. Instead, an attribute is assigned by having a separate KB.
So, if we talk about a "brown chair," then we're actually talking about two (or more) separate KBs, one that says we have a chair, and another that says, "the chair is brown."
So, although KBs don't have attributes, there are nonetheless different kinds of KBs. Some KBs identify physical objects (like chairs), and others describe attributes.
Still others are rules. For example, a child may see several brown chairs made of wood, and conclude that "All brown chairs are made of wood." This is an example of a rule KB that an intelligent computer might "learn," until the day that it encounters a brown chair made of plastic. This illustrates how rules might be learned and later refined.
How many different types of KBs are there? By referencing a thesaurus, I've come up a list of several hundred categories of English words, and each of those could arguably correspond to a type of KB. I'll describe this below.
The intelligent computer algorithm is going to have thousands of modules, and I can't make any attempt to do more than describe a few sample chunks of the algorithm.
An IC learns about physical objects by "noticing" them.
Noticing things is often called "attention to detail" in human beings. This is sometimes described in gender terms, that women have a greater attention to detail than men. For example, I could spend an hour talking to someone, and if you asked me later I probably couldn't tell you what color clothing he was wearing, but almost every woman I know would be able to do so.
It also relates to circumstances. A doctor examining a patient might notice something that a layman wouldn't notice. I wouldn't even notice an ordinary bird chirp in the distance, but a bird watcher would not only notice it, but would immediately classify it as to the type of bird.
When an IC notices something, then it can add to its set of KBs. For example, if there's a room full of chairs, the IC might or might not notice them. If it notices them, then it can add to its KB base a bunch of rules about what colors chairs can have, what chairs can be made of, and so forth.
There will have to be a number of "noticing" algorithms. In early versions, the IC will only notice things that it's told to notice. Later, it will develop rule KBs for noticing things. Such rules are usually in the form of "If something looks odd, then notice it."
For example, if the IC is looking for red chairs, it might notice a bunch of chairs in a room as a group, ignore all the non-red chairs, but then notice each red chair individually.
In humans, every object that's noticed seems to get a name in some way. It might be a person's name (that person introduced himself, and his name is Joe), or it might be a description (the chair that I sat on last night). If the IC notices an object, then the object itself is a KB, but there also has to be one or more KBs that identify the object in some way.
Quite possibly the greatest advantage that humans have over computers today is the ability to identify things by sound or by sight. As computer vision and voice recognition improve, computers will need to learn new things through these "senses."
Early versions of the IC will probably not depend on computer vision on more than a limited basis. Most of the "learning" processes will be done through natural language processing. For example, the Oxford English Dictionary (OED) is available on disk, and software can be written so that the IC can read the OED disk and "learn" from it by creating the necessary collection of KBs.
Once that's done, the IC will be able to "read" simple books, such as children's or high school level books. As time goes on, the IC will develop a reading skill just as a human learns to read, and eventually will be able to read complex texts. Once that point is reached, the IC will be able to learn almost anything very quickly.
I don't believe that it will take very long before this is possible. I think that by 2010 a supercomputer will be able to process text and learn from it.
The IC will also have to be able to learn from hearing spoken words and from seeing things. These are essentially pattern matching problems, and will be possible with more powerful computers that can perform massively parallel pattern matches in real time.
Algorithms will be developed to turn "hearing" and "vision" into KBs. Development of these algorithms will require help from experts in the fields of voice recognition and computer vision. These algorithms will be tied into other "noticing" and rule-building algorithms previously summarized.
How does the computer learn the Knowledge Bit: "Jane is Joe's sister"?
This is an example of how one KB is created from other KBs. The following description shows some of the steps involved in learning the above fact, and it illustrates how KBs fit together to form other KBs.
One of the first thing that a baby learns is the concept of "person." Mom and dad are persons, as are friends and parents' friends. Baby also learns that "I'm a person." However, confusion comes from the question, "Is Fido a person?"
It won't be so hard for the IC to learn what a person is, since it will be written into the software at the beginning.
At some point, the IC "noticed" a person, and somehow learned that this person has the name "Jane." There are many ways that the IC could have learned this -- through being told, or through a more complex inference. Human beings learn people's names in many ways -- talking to them in person or on the phone, seeing a photo, reading something they authored, and so forth. The IC will also have multiple algorithms for learning a person's name.
You learn what "married people" are in childhood. You see people in pairs -- your parents, neighbors, aunts and uncles. Later, you learn refinements: boy/girl friends, divorced couples. This same information will be taught to the IC.
These last two KBs could have been learned in numerous ways, as in the case of learning someone's names.
The IC might learn this in many ways, depending on its KBs and its capabilities. The name "Jane" is a pretty good indication, but there may also have been written text that refers to Jane as "she." With additional capabilities, the IC could identify a female by clothing and appearance, or by voice.
The IC could have learned this from scanning a dictionary and learning the definition of "sister."
This is the final step, where all the above KBs are combined into a new KB, "Jane is Joe's sister."
I'm not going to attempt to describe this algorithm, except to point out that a lot of work has been done on this sort of thing. "Expert systems," for example, are designed specifically to take sets of facts and rules and derive new conclusions. A person with expertise in expert systems would probably be the best person to implement this part of the IC algorithm.
As we've previously said, "self-awareness" means that the IC has self-preservation as a goal. This brings us to the whole problem of motivations and goal-setting.
At any rate, my point is that you implement things like self-awareness and motivations by implementing goals. There are transient goals -- "Your job today is to fix the plumbing" -- and there are permanent goals, such as might be implemented according to the example of Maslow's Hierarchy of Needs:
 |
I don't know what the analog to "love" would be for an intelligent computer, but at least it has to be thought through.
How does an IC achieve a goal? Once again, we can turn to expertise developed in expert systems. These systems have developed the technology of taking sets of rules, taking a goal as input, and finding a way from the rules to seek out the appropriate sub-goals, and finally arrive at the desired goal.
Just to give one more example, let's work through an example of reaching a goal. Suppose that an IC has as a goal or sub-goal the job of figuring all the people in the room who are somebody's sister.
Here's an outline of the steps:
Now, given a female person, how does the IC achieve the sub-goal of determining whether that female person is a sister?
The IC may already "know"; that is, there may already be an KB that says that that person is someone's sister.
Otherwise, it has to go through all its KBs, to search for ways that it's previously learned that someone was a sister. For example, the IC might search for all KBs that indicate that some person is a sister. The IC can then go back and figure out where the KB came from, and then go through the same steps with the new person, if possible.
I previously said that I wanted a way of describing different types of KBs. In order to do this, I went to a thesaurus, Roget's 21st century Thesaurus, edited by Barbara Ann Kipfer, PhD., Head lexicographer, Dell Publishing, 1993.
This book contains a "concept index" at the end which breaks 17,000 words down into 837 groups. The 837 groups appear in ten major categories broken into several dozen sub-categories.
Here's a list of the ten major categories, along with the sub-categories for each category:
Just to give you a better idea of how this works, notice that the "Causes" category contains two sub-categories, abstract and physical.
Here's a list of the groups that appear in the "Causes" category, sub-category "abstract": affect, event that causes another, state of causation, to be, to change, to change abstractly, to change an event, to change cognitively, to change number of quantity, to change or affect an event, to change state of being, to continue, to diminish, to function, to happen, to have, to improve, to increase quantity, to injure, to reduce quantity.
From the above groups, here's a list of the words that appear in the "To reduce quantity" group: abbreviate, abridge, abstract, alleviate, commute, compress, condense, contract, curtail, cut, cut back, deduct, deflate, detract, digest, discount, downsize, lessen, lower, minimize, modify, narrow, pure, prune, reduce, shorten, slash, summarize, take, trim, truncate, whittle
Here's a list of the groups that appear in the "Causes" category, sub-category "physical": to break, to burn, to change physically, to create, to destroy, to grow, to make dirty, to take hot or cold, to make wet.
From the above groups, here's a list of the words that appear in the "To burn" group: arson, blaze, burn, char, conflagration, fire, flame, flare, glow, ignite, inflame, kindle, lick, light, porch, scorch, sear, smolder
The above examples should give you a flavor of how the 17,000 words are broken down into groups, sub-categories, and categories.
It's quite possible that the IC algorithm will require considering each of the 17,000 words, or at least each of the 837 groups.
It may also be necessary to consider all relationships between pairs of words, but this list can be pared down substantially, and all the information can be obtained from the OED, if properly processed.
Now, this is a huge amount of work, and may require thousands of man-years of effort. But the point is that it's a fairly well-defined job that can be completed within a few years.
If you have a jigsaw puzzle of 1000 pieces, then there are 999,000 pairs of pieces to test if you want to find two pieces that fit together, and a powerful computer can do that instantly. But if the jigsaw puzzle has 1,000,000 pieces, then there are 999,999,000,000 pairs of pieces, something that even a powerful computer might take a great deal of time to do.
As time goes on, the IC collects more and more KBs, and the job of combining them in the right way becomes more and more time consuming.
Have you ever heard a word or phrase that "rang a bell" in your memory, but it took several minutes for you to remember why? That's because over a period of years, your brain had rearranged the information in your brain and pushed the memories back into "secondary storage" in your brain. As you wondered about the familiar phrase, your brain worked to retrieve all the information from "secondary storage" and move it to the front of your consciousness.
Have you ever gone to bed puzzled by a problem and woken up the next morning with a solution to the problem? That's because your brain was reorganizing KBs during the night to bring the ones that you need to the front of your consciousness.
Your brain is constantly rearranging KBs in your brain, bringing the most useful ones forward, pushing the less useful ones back. A lot of this activity takes place while you're asleep. That may actually be the most important purpose of sleep.
Intelligent computers will also need something analogous to "sleep." The time will be needed for the computer to rearrange the KBs in memory for the same purpose.
All of this is the job of the "memory management unit" in the block diagram.
The memory management unit has to do more. It has to learn, over a period of time, which of the KBs are going to be more important, and which are going to be less important.
A young human brain doesn't always know which KBs are important on a day to day basis and which are less important. For a human, this is often tied to "lessons learned" -- after you get humiliated and reprimanded for using a swear word in school, the rule about not using swear words stays pretty far forward in your consciousness.
As years go by, the process of rearranging knowledge bits gets better and better. In time, the most valuable KBs are always in the forefront of your consciousness, and that's how wisdom increases.
Whatever wisdom is, it's something that comes only from experience, and it's the reason that we depend on older generations to lead us.
... to be supplied
The above is a pretty reasonable algorithm, and it wouldn't surprise me if someone was implementing something like it already.
Early versions of this algorithm could be working by the early 2010s, producing useful results, perhaps in solving math problems or something like that. In the 2015 time frame, special purpose robots should be available to do things like fix plumbing or act as 24x7 nursing. By 2030 or so, fully functional super-intelligent autonomous robots will be available.
This is a fascinating software project, and anyone should be thrilled to be working on it.
In a later section, we're going to make the argument for a fairly audacious claim: That the Generational Dynamics model applies to all intelligent life in the universe.
But first, there's an important piece of business to take care of.
The representation of knowledge as Knowledge Bits (KBs) that can be fit together like jigsaw puzzle pieces provides us the opportunity to take a side trip and give an elegant partial proof that technology grows exponentially.
As we said when we described exponential growth (see p. [forecast#622]), population grows exponentially. That's easy to understand, as follows: The number of children and the number of deaths in a population (assuming that food and predators are unchanged) is equal to a constant fraction of the size of the population. From calculus we know that any quantity whose growth is proportional to its size must be exponential, and so the population grows exponentially.
But the exponential growth law for technology is far more mysterious. Why should technology grow at the same rate as people? What's the connection?
I've been aware of the law of exponential growth for technology since the 1970s, and I've always been fascinated by it. Over the years, I looked everywhere for a proof of the law, but I never found one. Finally, in recent years, Ray Kurzweil published his proof, and I'll come back to that later.
Our proof is very simple, and it's based on our development of KBs. New KBs are formed by fitting together existing KBs, in the same way that new people are born by the mating of two existing people. The number of new KBs that are "discovered" by scientists and engineers in any year depends on the number of KBs that have already been discovered. Therefore, the number of discovered KBs grows exponentially for exactly the same reason that population grows exponentially. Since technology equals the number of discovered KBs at any time, technology itself grows exponentially. QED
That's a very simple, elegant proof of exponential growth, but it has two flaws that have to be addressed.
The first problem is that it's not clear that the number of new KBs discovered each year is a constant proportion to the number previously discovered. It's clear in the case of population, since population growth is actually proportional to the number of women in the population. But in the case of KBs, there's no such clear indication.
In fact, it's probably not true. KBs can combine with one another in different ways, in pairs, triplets, and so forth. As the number of previously discovered KBs increases, there are more ways that they can be combined. Therefore, the number of new KBs discovered each year is probably an increasing fraction of the number previously discovered. Therefore, the number of Knowledge Bits grows faster than exponentially. In fact, Ray Kurzweil has found some evidence that this is the case in terms of computer power.
The second problem is more difficult: We've shown that technology grows exponentially, or even faster than exponentially, by showing that the number of KBs grows faster than exponentially. But why does that translate into specific exponential performance improvements?
As we discussed on page [forecast#622], the efficiency of artificial light has been growing exponentially for well over a century. Even if our knowledge about the efficiency of artificial light grows expontially, why does that mean that the efficiency itself grows exponentially?
The same question arises for computer power. If our knowledge about computer power grows exponentially, why should computer power itself grow exponentially?
Ray Kurzweil, in his paper The Law of Accelerating Returns, gives his proof of the exponential growth of technology, he states this as an assumption:
In other words, computer power is a linear function of the knowledge of how to build computers. This is actually a conservative assumption. In general, innovations improve V (computer power) by a multiple, not in an additive way. Independent innovations multiply each other's effect. For example, a circuit advance such as CMOS, a more efficient IC wiring methodology, and a processor innovation such as pipelining all increase V by independent multiples.
So Kurzweil wasn't able to make this jump either, and had to assume it.
That's why this has been called a "partial proof."
The Generational Dynamics paradigm appears to have prevailed throughout all places and times in human history, so it's not unreasonable to believe that it might be a requirement of all intelligent life, including extraterrestial life in other places in the universe.
We're going to make the argument that Generational Dynamics is a requirement in the evolution of intelligent life anywhere in the universe. This proposition isn't as far-fetched as it might seem, given that Generational Dynamics has been an extremely robust part of all of human history.
However, we're going to make this argument carefully. We'll begin by establishing some "axioms," assumptions that we believe have to be true of any evolution of human life.
Then we'll show that it follows from the axioms that the Generational Dynamics paradigm must apply to any intelligent life. That way, anyone who wishes to challenge the final claim need only indicate where the axioms go wrong, or where the logic of the follow-on conclusions go wrong.
By the way, we're well aware of the dangers of the approach we're using. The mathematician and philosopher Bertrand Russell once wrote:
Now, in the beginning everything is self-evident, and it's hard to see whether one self-evident proposition follows from another or not. Obviousness is always the enemy of correctness. Hence, we must invent new and even difficult symbolism in which nothing is obvious.
We choose to use an expository style that most readers can understand. We hope that we'll be sensible and analytical enough to avoid logic errors that we might have caught by using difficult symbolism.
If we're going to presume to create a model for the evolution of intelligent life elsewhere in the universe, then we ought to have an idea of what we mean by intelligence.
We assume that intelligence can evolve only in a manner consistent with the Intelligent Computer algorithm that we've just described. That is, intelligence is the process of putting together KBs (knowledge bits) together like jigsaw puzzle pieces, to create larger KBs.
So this takes us back full circle. We started from human intelligence and designed an algorithm for intelligent computers. Now we're saying that the algorithm for intelligent computers is the only one that describes intelligence.
What about the "five senses"? We can probably assume that every intelligent being has some ability to sense light forms and some ability to hear and interpret sounds, since light and sound are ubiquitous. Whether smell, touch and taste are present is more questionable, although we can assume there's some "substance-based" sense. Whatever senses a being might have, an intelligent being will need to learn from a massively parallel pattern matching mechanism.
How do we measure the level of intelligence? We do that easily by comparing it to the speed of a computer. There have been various estimates of the power of the human brain, but for simplicity we'll just say that the human brain power / intelligence level is 100 megaflops (able to do the equivalent of 100 million floating point operations per earth-second).
It's worth pointing out that even here on earth there's a continuum of intelligence among the animals. When little Timmy falls into a hole and his dog Lassie runs to get help, Lassie is reaching a conclusion that can't be completely explained by instinct or pattern matching. Some level of reasoning, albeit a very low level, is required.
This leads to:
Axiom. Any intelligent being has one or more "senses," implemented in the brain by some kind of massively parallel pattern matching; and also has a "logic capability" which operates according to the jigsaw puzzle model described earlier in this chapter. The level of intelligence can be measured by the power of an equivalent computer (100 megaflops for human beings).
On earth, the size of every population of species grows exponentially, as long as there's no external limitation (too little food, too many predators).
When you factor in external limitations, populations of species on earth do not grow exponentially. When the amount of food is limited in a region, then the population of a species in that region is also limited. If there are no serious predators, the individual will die of starvation, or individuals will fight one another for limited resources. Either way, the population of the species will remain relatively constant over long periods of time.
When predators are involved, the situation can be quite different. The population of some animals (some lemmings, for example) varies cyclically (sinusoidally), growing larger for several seasons, then decreasing for several seasons, then growing again, and continuing in that way. The reason is this: As the population grows, the predators become more numerous and they kill more individuals, whose population decreases. When enough have been killed, the predators no longer have enough to eat, and they starve to death, and the population of the target species grows again.
In most cases, natural selection occurs through one-on-one competitions between individuals of different species or sub-species. Wars are possible in some species (such as ants), but they're never more than mechanistic extensions of one-on-one competitions.
Since we're modeling worlds where intelligent life evolved, we must assume that natural selection (survival of the fittest) is occurring on those worlds, and that there's competition for some resource (food). We do not need to assume exponential growth of the population or the resource (food supply), but our development does require that we assume the need for periodic life or death competitions for some resource. We'll state this as an axiom, though it might also be stated as a conclusion from the fact that we're assuming that natural selection is occurring at all.
Axiom: Periodic life-or-death competitions (fights/wars) for resources occur as part of the natural selection mechanism.
The analysis of the preceding section doesn't have anything to do with intelligence. How does natural selection differ in the case of the evolution of intelligent beings?
We believe (and we're going to postulate) that a fundamental capability that intelligence gives us is the ability to communicate with one another and to form alliances if we desire. In other words, once you add intelligence to a species, then it changes from a population of isolated individuals or small groups that act by instinct into a population capable of forming large social groups and alliances.
Axiom: Members of an intelligent species are able to communicate with one another, and are capable of forming social groups and alliances. Furthermore, concepts of "loyalty" and "betrayal" can apply.
Axiom: Members of an intelligent species are able to choose strategically whether to achieve objectives by "politics" or by war.
We're now able to reach our first major conclusion: that intelligence implies the formation of identity groups and wars between identity groups.
The reasoning is pretty clear: Suppose that A and B are two sub-species that differ in this regard. Suppose the individuals in A compete for resources by one-on-one competitions (fights to the death), and suppose the individuals in B are intelligent enough to form alliances.
The group B will soon dominate by means of "gang strategy." The members of B will form gangs, and the gangs will "pick off" the individuals in A one by one. Thus, natural selection will favor sub-species that are capable of gangs for the purpose of competing for resources.
The same argument can be extended one step further: Suppose A is only intelligent enough to form small gangs, say up to 3 or 4 people, and suppose B is capable of forming larger gangs. Then the larger gangs of group B will be able to dominate with a "large gang strategy": create a large gang that picks off B's smaller gangs one by one.
On the other hand, gangs cannot get too large, or they become useless for natural selection competitions. The sub-species that will dominate is the one with the intelligence to have maximum flexibility in forming alliances: creating larger alliances when it's the best strategy, breaking off smaller alliances when that's the best strategy.
Finally, we can conclude that these alliances must have some persistence, because of the concepts of "loyalty" and "betrayal." The most intelligent species will have the flexibility to be loyal to or betray their alliances, depending on their interests. But since betrayors will be mistrusted and be unable to form further alliances, we can conclude that loyalty will occur frequently enough to provide for persistent alliances.
We'll call these alliances "identity groups." Among humans, identity groups are formed based on geography, religion, ethnicity, language, skin color, and other factors. When we model intelligent life elsewhere in the universe, we conclude the barest essentials, that identity groups exist, and they have wars with each other in competition for resources, and that the wars must be genocidal, and that the genocidal wars must occur periodically.
Conclusion: In any intelligent species, persistent identity groups will form.
Conclusion: In any intelligent species, identity groups will go to war with each other to compete for food or other resources.
Conclusion: Any intelligent species will have periodic genocidal wars among identity groups. The purpose of these wars is to gain access to more food (resources).
We've already come a long way toward showing that Generational Dynamics must apply to any intelligent species, anywhere in the universe. Starting from reasonable assumptions (axioms), we've already shown that intelligent species will have regular genocidal wars between identity groups. Having these kinds of genocidal wars is a by-product of intelligence.
We now wish to go one step farther, and show that intelligence implies that there are crisis and non-crisis wars in the sense demanded by Generational Dynamics. This will show that any intelligent species in the universe evolved with these two types of wars.
The reasoning is as follows:
We've actually proven something significant that goes beyond the concept of crisis and non-crisis wars:
Conclusion: An identity group's timeline can be split into two periods: crisis and non-crisis periods. Genocidal wars occur during crisis periods, and political wars may occur during non-crisis periods.
The next problem we want to tackle has to do with the fact that in Generational Dynamics, crisis wars are around 70-90 years apart, roughly the length of the human lifespan. We want to show that this relationship between cycle length and lifespan is universal.
The 80-earth-year timespan is firmly embedded in the human DNA. This comes from two observations. First, the 80-year maximum timespan seems to be constant at least back through ancient Greece, despite numerous advances that have significantly increased the average lifespan. And second, there are many people who are very influential business or government leaders in their 70s, but almost none in their 80s.
It seems manifest that 80 years is the maximum effective lifespan of human beings. We believe that evolution may have "experimented" with different lifespans over the eons, and finally settled on the lifespan that takes the best advantage of human intelligence -- long enough to gather wisdom and pass it on, short enough so that mind doesn't get too cluttered.
So how do we compute the maximum effective lifespan of an intelligent species elsewhere in the universe? We start with some axioms:
Axiom: An identity group has an advantage in genocidal war if its leaders have as much wisdom as possible.
Axiom: An identity group has an advantage in genocidal war if its total population is as youthful and vigorous as possible.
Axiom: Wisdom is gained with age, but the Law of Diminishing Returns applies to an individual gathering wisdom as he grows older. This means that he gathers less and less wisdom each year.
These axioms, all of which are perfectly reasonable for humans and (we hope) for any intelligent species in the universe, define a situation where an equilibrium must be reached: All other things being equal, a sub-species will lose vigor but gain strategically as the maximum effective age of its leaders increases.
In genocidal competitions between otherwise equal sub-species of an intelligent species, the sub-species whose leaders are closer to the equilibrium point will have an advantage in a genocidal war. Thus, natural selection will favor sub-species that get close to the equilibrium point.
This proof allows us to reach the following conclusion:
Conclusion: An intelligent species will evolve, by natural selection, to have a maximum effective lifespan at the equilibrium point where the advantage gained in genocidal war by increased wisdom of leaders is precisely equal to the advantage lost by reduced youth and vigor of a younger population.
We now come to the next result - that the crisis war cycle length approximately equals the maximum effective lifespan.
We can't prove this precisely, but we note that it isn't precisely true for humans either. What we've found in Generational Dynamics is that a new crisis war never begins until two generations have passed after the end of the preceding one, and more often when three generations have passed.
An identity group cannot afford to have too frequent genocidal crisis wars, since they're extremely costly in terms of lives, especially the lives of young soldiers. And by a previous axiom, a society has an advantage in a genocidal war if its total population is more youthful and vigorous.
Thus, based on our assumptions, natural selection will favor an intelligent sub-species that can use diplomatic skills until it can "replenish" its population for another crisis war. The time to do this is comparable to the length of a maximum effective lifespan.
Conclusion: The cycle length of crisis wars is comparable to the maximum effective lifespan of an intelligent species.
What about the individual generational eras - austerity, awakening, unraveling crisis? Can we find a way to show that intelligent life elsewhere in the universe will experience the same eras?
We might begin with axioms that assume that there's an "age of maturity" (20 for humans), and an age of maximum effectiveness as middle manager (40), and an age of maximum effectiveness for senior leadership (60). These are not unreasonable axioms, but it's hard to be as certain about them as about the others we've postulated. Furthermore, our development does not really require more than just the crisis war cycle, and so we can leave the individual generational eras as a subject for future study.
In the Generational Dynamics paradigm, individual identity groups' timelimes merge as multiple crisis war cycles pass. This is a consequence of technological development.
As technology improves, especially in the areas of communications and transportation, identity groups are able to merge together where they couldn't before, and natural selection will favor sub-species that are flexible enough to form larger identity groups when that provides an advantage in genocidal wars.
It's fairly certain that technology developments will proceed in intelligent species elsewhere in the universe as they have here on earth. After all, you need to invent the wheel before you can invent the automobile.
Technology development on earth has followed a steadfast exponential growth path, and we can expect that the same is true for all intelligent species. Furthermore, we can reasonably expect that the rate of exponential growth depends on the intelligence of the species which, as we've previously indicated, we can measure by means of the equivalent computer power in megaflops.
However, our development doesn't really turn on the rate of technological growth. We only need to know that technology will improve, just as it has for humans.
In time, communications and transportation technology will improve to the sophisticated level that it has on the earth. At such time, all the major crisis war timelines will merge into a single one, as is happening to the human race today.
And we can also reasonably conclude that, at some point, every intelligent species, everywhere in the universe, will eventually reach: The Singularity.
We've now concluded that wherever intelligent life has evolved anywhere in the universe, the evolution has paralleled the evolution of human life, as described by Generational Dynamics theory. In particular, we've concluded that every intelligent species goes through the same cycle of crisis wars, with timelines that eventually merge into a single major crisis war, and technology development that reaches the level of The Singularity.
Since every burst of intelligent life throughout the universe is evidently going to reach The Singularity, then what can we say about what comes after The Singularity?
Let's speculate.
Everyone seems to agree that technology development will speed up significantly after the Singularity. Intelligent computers will continue improving their capabilities, and each cycle of improvement will improve their powers of scientific discovery and invention, so that the next round of discoveries will come even faster. Some suggest that within ten years later, every possible scientific will discovery have been made, and every possible invention will have been invented.
That particular claim can't be proved, of course. In fact, think back to the "butterfly effect," that we discussed on page [forecast#702]. Remember what it means: That no matter how good the science gets, not matter how fast computers get, it will always be mathematically impossible to predict the weather more than several days in advance. We also know from the mathematics of Recursive Function Theory and Algorithmic Computation Theory that some things can never be known, and other things will take too long to be known, no matter how powerful your computers are. So there will be some limits, even after the Singularity.
Still, by the Law of Diminishing Returns, it's quite reasonable to believe that within a few decades the world will reach a kind of "Singularity #2," where, for whatever reason, there's nothing significant left to discover or invent.
In fact, I'll make that statement a little stronger: As the number of iterations of self-improvement increase, the Intelligent Computers' capabilities will approach a limiting state.
Recall that earlier in this chapter I made the point that human beings will write Version 1.0 of the Intelligent Computer software, and that we'd better write it correctly if human beings are going to survive, because future versions of the software will be written by Intelligent Computers themselves.
That statement is still true, but it has to refined: No matter how version 1.0 is written, whether it's written poorly or well, as it goes through version 2.0, 3.0, 4.0, ..., 1000.0, 1001.0, 1002.0, ..., it will approach a fixed limiting point which cannot be avoided. From the point of view of Chaos Theory, this limit point is a point attractor, a "Basin of Attraction" (p. [forecast#847]) to which the new versions of the Intelligent Computers will be attracted, irrespective of the first version. That will be a kind of "steady state" point, a kind of Singularity #$2. The rapid blast of changes, discoveries and inventions that occur in the intermediate period between the two singularities will be over, and there'll be nothing left to change. This point will probably be reached before the end of this century. (We're making an unproved assumption here, that there's only one limit point, but intuition and experience lead us to believe that that assumption is true.)
What will that world be like? Will humans exist? Will animals, insects, plants, bacteria, and other forms of life still exist? If humans can continue to survive through the intermediate period between Singularity #1 and Singularity #2, then I suppose it's reasonable to believe that they'll continue to survive during the steady state period, co-existing in some way with the intelligent computers. Will there be wars? Or will the steady state world be the world that so many people have dreamed about, a world where people finally live in peace, a peace enforced by intelligent computer rulers "who" will, among other things, prevent women from having so many children that population will increase.
Here's a final word for religious readers, and I'm referring specifically to Christians. The Bible book of Revelations talks about a final battle, followed by a millennium of peace. Perhaps the realization of this prophecy will be the uncontrolled, frenetic and bloody intermediate period, followed by a millennium of peace that beings with Singularity #2. Believers in other religions might find a way to fit their religions' "last days" prophecies into the period following the Singularity.
Some time ago, scientists began to realize that our radio and television programs were electromagnetic transmissions that were being transmitted outward to the universe, as well as inward to our homes. That led to the realization that if we were transmitting such electromagnetic signals to the universe, then other intelligent beings elsewhere in the universe might be doing the same thing.
This has led to a decades-long search for electromagnetic transmissions from other star systems. This project, often called SETI (the Search for Extraterrestrial Intelligence) has been a serious project, funded by numerous government and private agencies. The leading public agency, founded in 1984, is the SETI Institute at http://www.seti.org.
When the search began in 1960, I think many scientists hoped we would have discovered something by now. So after several decades, why haven't we verifiably detected extraterrestial life?
Some scientists have speculated that the reason is that human beings on earth are the first intelligence species in the universe, or at least in our galaxy, and since we're the first, there's no one else to find.
I have a different proposed explanation.
We've concluded that every intelligent species in the universe is evolving according to the same Generational Dynamics paradigm as on earth, including finally reaching the Singularity. So we can reasonably assume that there are already many places in the universe where the steady state Singularity #2 has been reached.
In any such steady state world, it's quite possible that there are no more electromagnetic transmissions. Indeed, we've almost eliminated the need for them in our world, as more and more radio and television signals are transported over the Internet.
Two more speculations. The first is that with all these steady state worlds, maybe millions or billions of them, scattered around the universe, all of them having discovered and invented everything that there is to discover and invent, it's possible that they're in communication with each other in some vast inter-galactic network, and are just leaving each other alone. (Of course, inter-galactic war is another possibility, but let's leave that.)
The second speculation is that this network of steady state worlds knows about us, and they're just waiting for us to reach Singularity #2 so that we can join their network.
This brings to mind the Prime Directive of the Star Trek television series and movies:
As the right of each sentient species to live in accordance with its normal cultural evolution is considered sacred, no Star Fleet personnel may interfere with the healthy development of alien life and culture. Such interference includes the introduction of superior knowledge, strength, or technology to a world whose society is incapable of handling such advantages wisely. Star Fleet personnel may not violate this Prime Directive, even to save their lives and/or their ship unless they are acting to right an earlier violation or an accidental contamination of said culture. This directive takes precedence over any and all other considerations, and carries with it the highest moral obligation.
This Prime Directive was formulated by script writers during the 1960s Awakening Era, and it represented a statement of a kind of interstellar multiculturalism.
But maybe the Prime Directive is actually practiced by this network of steady state worlds, "who" watch worlds around the universe with evolving intelligent species and follow a Prime Directive of not interfering with their culture until after Singularity #2.
In a book like this one, which is chock full of predictions that aren't so happy, it's nice to end this chapter on one which is actually full of hope, and hints that human beings may turn out to be all right after all.